Princes Disguised in Uniforms
Abstract
We revisit the secretary problem as a mathematical fairy tale: Princes wooing a princess sequentially arrive each having a qualification score originating from a known parametric distribution with all parameters known, e.g., the standard uniform distribution or the normal distribution with known mean and variance. For this so called full information game the question of interest is: How does the optimal strategy look, which maximizes the expected score of the selected candidate? As a further twist: How does the strategy change, if we sequentially have to estimate the parameters of the distribution alongside? The later variant is called the partial information game and is nicely addressed using sequential Bayesian updating.
 This work is licensed under a Creative Commons
Attribution-ShareAlike 4.0 International License. The
markdown+Rknitr source code of this blog is available under a GNU General Public
License (GPL v3) license from github.
This work is licensed under a Creative Commons
Attribution-ShareAlike 4.0 International License. The
markdown+Rknitr source code of this blog is available under a GNU General Public
License (GPL v3) license from github.
Introduction
In the last blog post Optimal Choice - Mathematical Advice for Real Life our interest was in determining a strategy to select the overall best candidate from a sequence of \(n\) candidates (e.g. princes, job candidates, houses, bids or tinder profiles) arriving sequentially. It was shown that the optimal strategy is to screen a number of candidates \(r-1\) in order to form a baseline and then, starting from the \(r\)’th candidate, select the first candidate better than the baseline. If no candidate was chosen before the \(n\)’th candidate this last candidate has to be selected no matter what. The natural phenomena of getting desperate towards the end was observed, if the objective of finding the best is changed to maximizing the expected rank of the selected candidate.
In this blog post we study the situation, where additional information about the absolute score of the candidates (instead of just their relative ranks) is available. In particular we assume that the candidate scores are known to originate from a known underlying distribution, e.g. the uniform or the standard normal. This means that not only the underlying parametric family of the scores are known, but also the parameters of the distribution. In what follows we use the work of Guttman (1960) to describe the problem in mathematical notation and discuss solution strategies. Then we move on to the work of Stewart (1978) in order to investigate how the strategy changes, if we also have to simultaneously estimate the parameters of the distribution alongside. R code implementing the optimal strategies is provided for both situations in order to enable prudent decision support for real-life problems.
Methods
Let the score of a candidate be represented by a random variable \(X\) with continuous probability density function \(f\) having support on \((a,b)\), where \(a<b\). Note that \(a\) and \(b\) are allowed to be \(\pm \infty\), respectively. Let \(F\) be the corresponding cumulative distribution of the score. Furthermore, let \(\mu=E(X)=\int_{a}^b x \cdot f(x) dx\) be the expectation of \(X\). In what follows we will assume that the distribution is such that the expectation exists. Assuming a total of \(n\) candidates, we ascertain that their abilities/scores are independently and identically sampled from this distribution, i.e.
\[ X_1,\ldots,X_n \stackrel{\text{iid}}{\sim} F. \]
The \(n\) candidates arrive sequentially and for each candidate one has to decide whether to select this candidate or to keep looking at further candidates. Once a candidate is rejected there is no opportunity to regret this choice later.
Now we denote by \(E_{n}\) the expected score of the chosen candidate when one has to choose among \(n\) candidates according to some pre-described strategy. It is immediately obvious that \(E_1=\mu\). If there are \(n\) candidates we would like to find the optimal stopping rule maximizing \(E_n\). The standard stopping rule based on the expectation implies that we would already stop at the first candidate, if the observed value \(x\) is such that \(x > E_{n-1}\). As a consequence,
\[ \begin{align*} E_{n+1} &= P(X > E_n) \cdot E(X\>|\>X \geq E_n) + P(X \leq E_n) \cdot E_n \\ %&= \int_{E_n}^b x \cdot f(x) dx + E_n \int_{a}^{E_n} f(x) dx \\ &= \int_{E_n}^b x \cdot f(x) dx + E_n \cdot (1-F(E_n)). \end{align*} \]
A function to perform these computations in R handling either general densities using numeric integration or analytic derivations would be:
######################################################################
##Compute E vector using either numerical integration, a function for
##the computation of E[n+1] or using the analytic solution of
##\int_{E_n}^b x df(x) dx.
##
## Parameters:
## n - number of candidates
## df - density function of the score distribution (i.e. f)
## pf - cumulative density function of the score distribution (i.e. F)
## intE_fun - function g(E_n) = \int_{E_n}^b x*f(x)dx (if available)
## Enp1_fun - function h(n,E_n) directly computing E_{n+1} from E_{n}
##
## Returns a vector of length (n+1) containing (E_0,...,E_n)'.
######################################################################
compute_E <- function(n,df,pf,intE_fun=NULL,Enp1_fun=NULL,...) {
E <- rep(NA,n+1)
E[1] <- 0
target <- function(x) x*df(x,...)
for (n in seq_len(length(E)-1)) {
if (is.null(Enp1_fun)) {
if (is.null(intE_fun)) {
E[n+1] <- integrate(target,E[n],Inf)$value + E[n] * pf(E[n],...)
} else {
E[n+1] <- intE_fun(En=E[n]) + E[n] * pf(E[n],...)
}
} else {
E[n+1] <- Enp1_fun(n=n,En=E[n],...)
}
}
return(E)
}Altogether, the optimal stopping time is thus
\[ T_{\text{stop}} = \min_{1\leq i \leq n} \left\{x_i > E_{n-i}\right\}. \]
The sequential comparisons can be given in the same strategy vector format as for the secretary problem post, i.e. one selects the candidate \(i\) if \(x_i>s_i\).
######################################################################
## Strategy of full information variant of the secretary problem
##
## Parameters:
## n - number of candidates
######################################################################
strategy_fip <- function(n,df,pf,intE_fun=NULL,Enp1_fun=NULL,...) {
E <- compute_E(n=n,df=df,pf=pf,intE_fun=intE_fun,Enp1_fun=Enp1_fun,...)
s <- E[(n-1:n)+1]
return(s)
}Example: U(0,1)
Example: In the case of \(X\sim U(0,1)\) we can analytically compute \[ E_{n+1}=\frac{1}{2}(1-E_n^2) + E_n^2 =\frac{1}{2}(1+E_n^2). \]
Given this setup, an R implementation of the strategy with, say, \(n=11\) looks as follows.
strategy_unif <- function(n) {
strategy_fip(n,Enp1_fun=function(n,En) {1/2*(1+En^2)})
}
(s_unif <- strategy_unif(n=11))## [1] 0.861 0.850 0.836 0.820 0.800 0.775 0.742 0.695 0.625 0.500 0.000We can thus compare the computed expectations by simulation:
## Simulate selection from n candidates if following the strategy s.
simulate <- function(n,s) {
x <- runif(n)
select_idx <- which.max(x > s)
c(score=x[select_idx],select_idx=select_idx,isOverallBest=(rank(x)[select_idx] == n))
}
## Small simulation study to get expected score of the selected candidate
res <- replicate(1e5,simulate(n=length(s_unif),s=s_unif))
apply(res,1,mean)## score select_idx isOverallBest
## 0.871 4.953 0.530tail(compute_E(n=11,Enp1_fun=function(n,En) {1/2*(1+En^2)}),n=1)## [1] 0.871As always, an animation says more than 1000 words and a few equations:
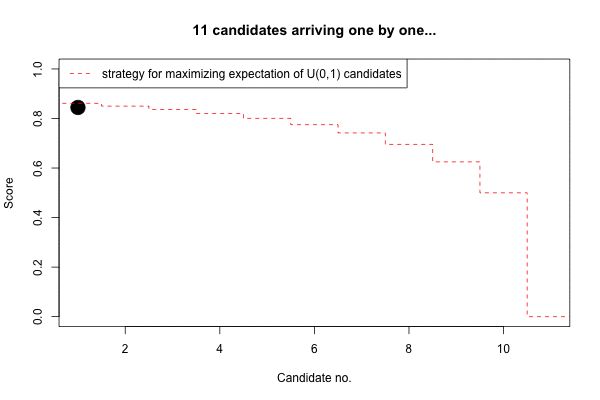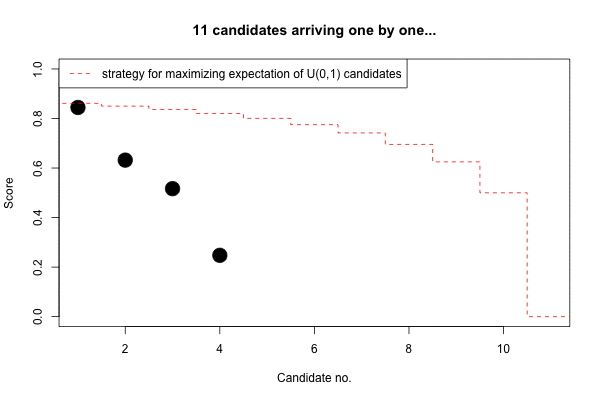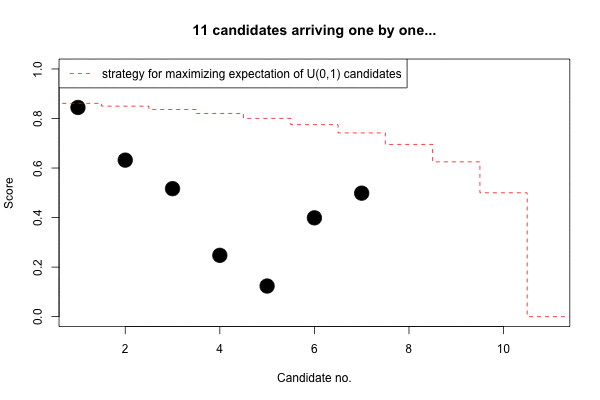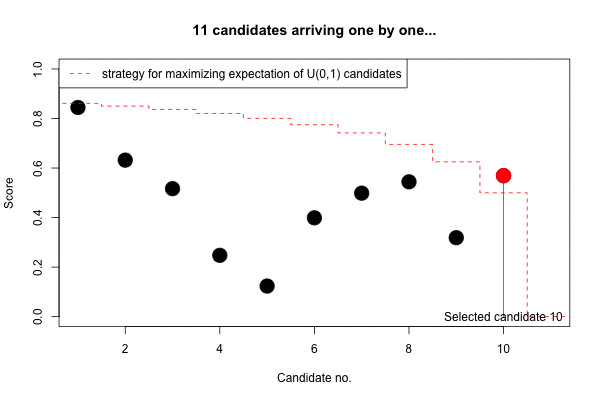
Finally, we can see how the expected score develops with increasing \(n\).
| 10 | 100 | 1000 | |
|---|---|---|---|
| score | 0.862 | 0.981 | 0.998 |
| select_idx | 4.589 | 34.943 | 333.724 |
| isOverallBest | 0.544 | 0.426 | 0.409 |
Gilbert and Mosteller (1966) provide an approximation for the expectation:
E_optE <- function(n) { 1-2/(n+log(n+1)+1.767) }which we can compare the scorecolumn of the above
simulation results:
| 10 | 100 | 1000 |
|---|---|---|
| 0.859 | 0.981 | 0.998 |
Altogether, this shows a pretty good agreement between the approximation and simulation results.
Example N(0,1)
## Compare results for the normal distribution (with and without
## analytic solution for 1st integral of the E[n+1] formula
strategy_fip(n=11,df=dnorm,pf=pnorm)## [1] 1.324 1.276 1.223 1.162 1.092 1.011 0.913 0.790 0.630 0.399 0.000(s_norm <- strategy_fip(n=11,df=dnorm,pf=pnorm,intE_fun=function(En,...) {
1/2*sqrt(2)*exp(-1/2*En^2)/sqrt(pi)
}))## [1] 1.324 1.276 1.223 1.162 1.092 1.011 0.913 0.790 0.630 0.399 0.000Note that by transforming the observations by the CDF \(F\), i.e. \(Y_i=F(X_i)\) we for any continuous
distribution obtain \(Y_i
\stackrel{\text{iid}}{\sim} U(0,1)\). Hence, the result of
comparing the \(X_i\) against
s_norm is the same as comparing \(F(X_i)\) against s_unif.
set.seed(1)
x <- rnorm(n=11) ; y <- pnorm(x)
c(which.max(x > s_norm), which.max(y > s_unif))## [1] 4 4It is thus not necessary to derive the optimal strategy for each possible continuous distribution. Instead one can transform the score to the uniform score as illustrated above and then use the corresponding strategy for the uniform to determine the stopping time.
The Partial Information Game
To summarise the previous section’s findings: knowing the candidate’s score distribution means that no training sample is needed to form a baseline. Hence, in the full information game, one immediately is ready for action: if a candidate with an excellent score is met early you do not hesitate! However, in a real word applications the parameters of the parametric distribution are likely to be unknown. This is known as the partial information game and here statistical inference actually for the first time plays a role, because one needs to learn about the parameters of the distribution while candidates arrive and while simultaneously deciding to select the current candidate or keep looking.
Stewart (1978) discusses a Bayesian approach to sequential learning the upper and lower limits of the underlying but unknown \(U(\alpha,\beta)\) distribution. Inspired by DeGroot (1970), a conjugate bilateral bivariate Pareto distribution on \((\alpha,\beta)\) is used. In what follows we describe this approach and the resulting selection strategy.
We will assume a bilateral bivariate Pareto distribution as joint prior distribution for \(\alpha\) and \(\beta\), i.e. the hierarchical Bayesian model is
\[ \begin{align*} (\alpha,\beta) & \sim \text{bPar}(k,l,u) \\ X_i \>|\> \alpha,\beta & \stackrel{\text{iid}}{\sim} U(\alpha,\beta), & i=1,\ldots,n, \end{align*} \]
where the density of the \(\text{bPar}(k,l,u)\) distribution is \[ f(\alpha,\beta) = \frac{k(k+1)(u-l)^k}{(\beta-\alpha)^{k+2}} \cdot I(\alpha<l \text{ and } \beta > u). \]
Here, \(k>0\) is a shape parameter and \(I(\>)\) denotes the indicator function. In other words, the parameter \(l\) is an upper bound for the lower limit of the uniform (i.e. \(\alpha\)), and the parameter \(u\) is a lower limit for the upper limit of the uniform (i.e. \(\beta\)). We can think of \((-\infty,l)\) as our prior interval for the worst possible candidate applying and \((u,\infty)\) as our prior interval for the best possible candidate. The shape parameter \(k\) denotes how concentrated the prior density is near the limits \(l\) and \(u\), respectively.
In the example: the princess may think entitlements and the cool future title (king) ensures that the worst possible prince up for wooing her would at least be a five. Similarly, the lower bound on the upper limit means that the princess initially thinks that due to her stingy dad (the current king) the best overall applicant might, in worst case, just be about a seven. Finally, the parameter \(k\) quantifies the strength in her prior belief - the higher \(k\) the closer the true limits are to the values of \(l\) and \(u\). Since the princess is unsure how well her prior is suited, she assumes a low value of \(k\), say, \(k=0.1\).
#################################################
# Joint bilateral Pareto prior
#
# Parameters:
# theta - vector length two containing (alpha,beta)
# k - parameter
# l - upper bound for alpha (i.e. an upper bound for the true lower bound)
# u - lower for beta (i.e. a lower bound for the true upper bound)
################################################
f_pareto <- function(theta,k,l,u) {
if (is.matrix(theta)) {
alpha <- theta[,1] ; beta <- theta[,2]
} else {
alpha <- theta[1] ; beta <- theta[2]
}
#Compute PDF
ifelse(alpha < l & beta > u,
k*(k+1)*(u - l)^k / (beta-alpha)^(k+2), 0)
}We illustrate the prior setting consisting of \(l=5\) and \(u=7\) and the two values \(k=0.1\) and \(k=1\):
## Warning: stat_contour(): Zero contours were generated## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf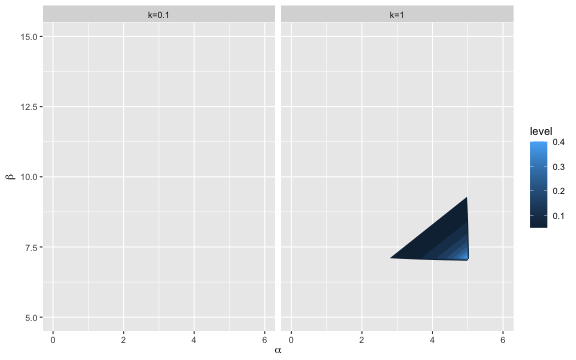
And the marginal density for two slices of the above joint density is:
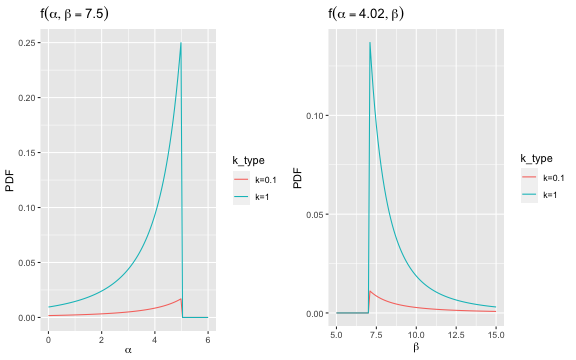
An important feature of this bivariate Pareto prior is that it is the conjugate prior to uniform sampling (DeGroot 1970). In other words, if \((\alpha,\beta) \sim \text{bPar}(k,l_0,u_0)\) and observations \(X_1,\ldots,X_i \stackrel{\text{iid}}{\sim} U(\alpha,\beta)\) become available, then the posterior distribution of interest is
\[ (\alpha,\beta)' \>|\> X_1,\ldots,X_i \sim \text{bPar}(k+i,l_i,u_i), \] where \[ \begin{align*} l_i &= \min(l_0,x_1,\ldots,x_i), \\ u_i &= \max(u_0,x_1,\ldots,x_i). \end{align*} \] In other words, the posterior depends only on \(l_i\) and \(u_i\) and not the individual \(x_i\)’s. Let \(\gamma_i\) be the obtained score, if we at stage \(i\) select the \(i\)’th candidate. Furthermore, using the same expectation definition as in the previous section, let \(E_i\) be the expected score obtained by following a particular strategy from the \(i\)’th candidate to the \(n\)’th candidate.
\[ \begin{align*} \gamma_n &= x_n \\ E_i &= E(\gamma_i | x_1,\ldots, x_{i-1}), & i \leq n, \\ \gamma_i &= \max(x_i, E_{i+1}), & i < n. \end{align*} \]
Stewart (1978) then shows that the optimal strategy is found by the following approach, which we here for simplicity shall program directly in R:
## Small helper function to convert between index 0 and R's index 1 storing
idx <- function(i) i+1
## Compute delta vector, which is a helper-vector in the solution of Stewart (1978)
compute_delta <- function(n, k) {
#Define delta's
delta <- rep(NA,n+1)
delta[idx(n-1)] = 1/2
for (i in rev(seq_len(n-1))) {
if (delta[idx(i)]>1) {
delta[idx(i-1)] <- delta[idx(i)]
} else {
delta[idx(i-1)] <- 1/2*(1+(k+i-1)/(k+i+1)*delta[idx(i)]^2) + (k+i-1)*delta[idx(i)]/(k+i+1)/(k+i-2)
}
}
return(delta)
}
###############################################################
## Bayesian sequential learning for a sequence of scores using the
## procedure described in Stewart (1978)
##
## Parameters:
## x - vector of candidate scores (scores are only revealed sequentially)
## prior - list containing prior values for k, l and u
###############################################################
strategy_pig <- function(x, prior) {
#Extract and precompute
n <- length(x)
delta <- compute_delta(n,k=prior$k)
#Generate data_frame to work on
seq <- data_frame(i=c(0,seq_len(n+1)),x=c(NA,x,NA), delta=c(delta,NA))
#Sequential updating of l and u from the data
l <- cummin(c(prior$l,x))
u <- cummax(c(prior$u,x))
seq <- seq %>% mutate(l=c(l,l[n]),u=c(u,u[n]),im1div2=i-0.5)
##Compute expectation
seq <- seq %>% mutate(E=lag(delta)*lag(u) + (1-lag(delta))*lag(l))
##Decision boundary
seq <- seq %>% mutate(threshold=delta*u + (1-delta)*l, rank=rank(x),isOverallBest=(rank == n))
#Ensure that last candidate is always taken
seq[n+1:2,"threshold"] <- min(x)
##Find r_1 and return there characteristics
r1 <- seq %>% filter(delta <= 1 & i < n & i > max(0,2-prior$k)) %>% slice(1) %>% select(i) %>% as.numeric
select <- seq %>% filter(i >= r1) %>% filter(x >= threshold) %>% slice(1)
return(list(seq=seq,select=select))
}We now simulate a particular scenario consisting of 11 princes wooing a princess and apply the optimal selection strategy applying the princess’ prior:
##Prior info
prior <- list(k=0.1,l=5,u=7)
##Reverse engineering a happy end! :-)
# which(sapply(1:100, function(i) {
# set.seed(i); x <- runif(n=11,0,10)
# s <- strategy_pig(x, prior=prior)
# as.numeric(s$select[,"isOverallBest"])
# })==1)
##Sample princes from an uniform with unknown limits -- here X_i \sim U(0,10)
set.seed(8)
x <- runif(n=11,0,10)
s <- strategy_pig(x, prior=prior)## Warning: `data_frame()` was deprecated in tibble 1.1.0.
## Please use `tibble()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.s$select## # A tibble: 1 × 10
## i x delta l u im1div2 E threshold rank isOverallBest
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
## 1 8 9.32 0.745 2.08 9.32 7.5 6.88 7.47 11 TRUE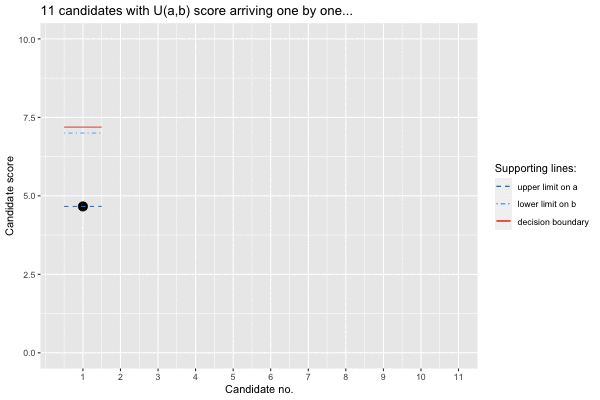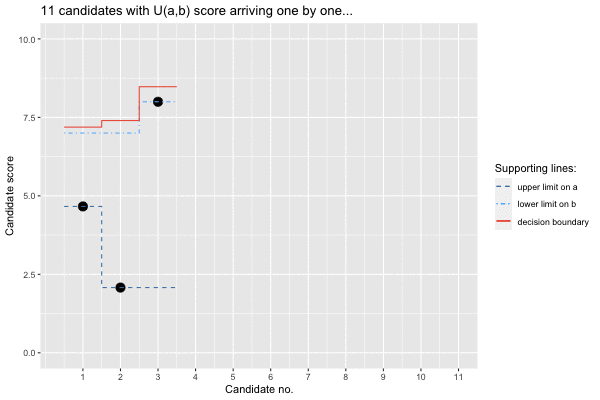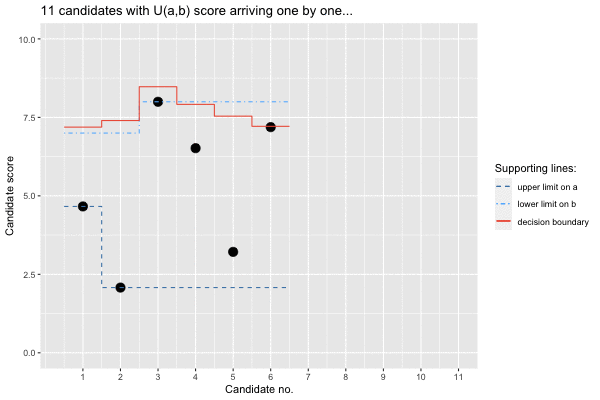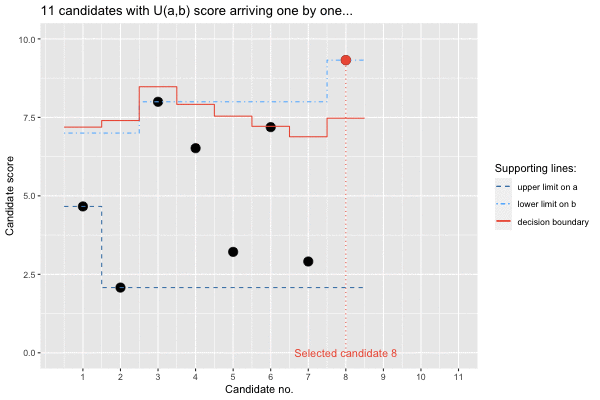
The animation provides interesting insights: Firstly, the upper bound
on the lower limit is updated along the way, because some seriously
unfit candidates dare to woo. Secondly, the decision boundary is
initially slightly above our lower bound on the upper limit. However,
the first candidate (candidate no. 3) above this prior bound is not
accepted, since it is still early in the sequence and thus little is
known about the support of the uniform, i.e. the range of candidates
applying. Hence, the princess hopes to get an even better candidate.
However, as time passes by and no such candidate appears, the limit is
slowly adjusted downwards. Luckily, the 8’th candidate not only brings a
score better than imagined (and is thus selected), he also (seen through
the omnipotent eyes of somebody knowing all the candidates) actually is
the best prince among all the candidates,
i.e. isOverallBest=TRUE. In other words: our mathematical
fairy tale even has a happy end!

Discussion
The full information game provides a good baseline to see the difference between having no information but the rank of candidates and knowing the distribution of the candidate’s score. More references and variants of the secretary problem can be found in Freeman (1983).