Happy pbirthday class of 2016
Abstract
Continuing the analysis of first names given to newborns in Berlin
2016, we solve the following problem: what is the probability, that in a
school class of size \(n\) of these
kids there will be at least two kids having the same first name? The
answer to the problem for classes of size 26 is 34% and can be solved as
an instance of the birthday problem with unequal probabilities. R code
is provided for solving the problem exactly for moderate \(n\) and approximately for larger \(n\). For the case that all probabilities
are equal, our results are compared to the output of R’s lovely
pbirthday function.
 This work is licensed under a Creative Commons
Attribution-ShareAlike 4.0 International License. The
markdown+Rknitr source code of this blog is available under a GNU General Public
License (GPL v3) license from github.
This work is licensed under a Creative Commons
Attribution-ShareAlike 4.0 International License. The
markdown+Rknitr source code of this blog is available under a GNU General Public
License (GPL v3) license from github.
Introduction
The previous post Naming Uncertainty by the Bootstrap contained an analysis of first names given to newborns in Berlin 2016 (Landesamt für Bürger- und Ordnungsangelegenheiten Berlin 2017). For instance, Marie and Alexander were the top names among girls and boys, respectively. In a comment Maëlle asked what’s the resulting probability that there will be kids with the same first name in a school class? We implement equations by Klotz (1979) and Mase (1992) in R in order to answer this important question.
The Birthday Problem
The above posed question is a variation of the birthday problem, which every statistician has solved at least once in an introductory probability class: in a class of \(n\) randomly chosen persons, what is the probability that some pair of them will have the same birthday? Assuming that there are \(N=365\) possible birthdays and all birthdays are equally probable the answer can be calculated as:
\[ P(\text{at least two people in the class have the same birthday}) = 1-\frac{(N)_{n}}{N^n}, \]
where \((x)_n = x! / (x-n)!\) is the
so called factorial polynomial. Say we are interested
in \(n=26\), which is the maximal
allowed class size in Berlin’s elementary schools (§4, Sect. 8 in
the regulation). We can perform the necessary calculations either
directly or by R’s pbirthdayfunction.
n <- 26 ; N <- 365
c(manual=1 - exp(lfactorial(N)-lfactorial(N-n) - n*log(N)),
pbirthday=pbirthday(n=n,classes=N))## manual pbirthday
## 0.5982408 0.5982408Finding the pbirthday function as part of base R was a
bit surprising, but just underlines that R really has its roots in
statistics!
Birthday Problem with Unequal Probabilities
In our problem \(N\) corresponds to all possible names of newborns in 2016. For the analysis we only group by first name and thus do not distinguish between instances of the same name used for both girls and boys.
newborn <- distrNames %>% group_by(firstname) %>%
summarise(count=sum(count)) %>% ungroup() %>%
mutate(p=count/sum(count)) %>%
arrange(desc(count))## # A tibble: 13,245 × 3
## firstname count p
## <chr> <int> <dbl>
## 1 Marie 695 0.009996404
## 2 Sophie 649 0.009334772
## 3 Charlotte 495 0.007119741
## 4 Alexander 468 0.006731392
## # ... with 1.324e+04 more rowsIn total there are \(N=13245\) possible names. From the \(p\) column it also becomes obvious that not all names are equally likely. Had they been, the quick solution to Maëlle’s question would have been:
pbirthday(n=26, classes=nrow(newborn))## [1] 0.02425434Less than 3%! However, we expect this probability to be much higher, if we start to take the unequal occurrence probabilities into account. So let’s do it!
It’s easy to see that the probability of no collision, i.e. no kids having the same name in the class, can be calculated as: \[ P(\overline{C}_n) = n! \underset{1\leq i_1 < i_2 < \cdots <i_n \leq N}{\sum \sum \cdots \sum} \> p_{i_1} p_{i_2} \cdots p_{i_n}. \]
However, this is a formidable number of terms to sum. In the case of \(N=13245\) and \(n=26\) the number is:
Rmpfr::chooseMpfr(N,n)## 1 'mpfr' number of precision 294 bits
## [1] 360635627424461042343649241991659010127226742008898829465568350273963478046740130That’s an 81 digit number! This is not ever going to happen. Instead Klotz (1979), based on generating functions, showed that the above equation corresponds to
\[ P(\overline{C}_n) = n! \underset{\underset{\sum_{j=1}^n j \cdot t_j = n}{0\leq t_1,t_2,\ldots,t_n \leq n}}{\sum \sum \cdots \sum} (-1)^{n + \sum_j t_j} \left( \prod_{j=1}^n \frac{ (P_j/j)^{t_j}}{t_j!} \right), \] where \(P_j = \sum_{i=1}^N p_i^j\). Let the vector \(\mathbf{t}=(t_1,\ldots,t_n)\) count the number of singletons (\(t_1\)), doubletons (\(t_2\)), triplets (\(t_3\)), …, up to the number of names occurring \(n\) times (\(t_n\)). The above sum means that we have to sum over all \(\mathbf{t}\) such that \(\sum_{j=1}^n j \cdot t_j = n\). The number of such terms to sum is much lower than in the previous expression, e.g., for \(N=13245\) and \(n=26\) the number of terms is 2436.
The above computations have been made available in the R package birthdayproblem
available from github:
devtools::install_github("hoehleatsu/birthdayproblem")As an example, for \(n=4\) all the necessary terms to sum can be found somewhat brute-force’ish by running through the following four nested for loops:
## compute_tList <- function() {
## n <- 4
## tList <- NULL
## for (t4 in 0:floor(n/4)) {
## for (t3 in 0:floor(n/3)) {
## for (t2 in 0:floor(n/2)) {
## for (t1 in 0:floor(n/1)) {
## t <- c(t1,t2,t3,t4)
## if (sum( (1:n)*t) == n) tList <- rbind(tList, t)
## if (sum( (n:(n-4+1)*t[n:(n-4+1)])) > n) break;
## }
## if (sum( (n:(n-3+1)*t[n:(n-3+1)])) > n) break;
## }
## if (sum( (n:(n-2+1)*t[n:(n-2+1)])) > n) break;
## }
## if (sum( (n:(n-1+1)*t[n:(n-1+1)])) > n) break;
## }
## return(tList)
## }This function would then return the necessary sets for the \(n=4\) case:
## [,1] [,2] [,3] [,4]
## t 4 0 0 0
## t 2 1 0 0
## t 0 2 0 0
## t 1 0 1 0
## t 0 0 0 1which can be processed further as in the Klotz (1979) equation stated above in order to compute the probability of interest.
In the accompanying R
code of this blog post the above \(n\) nested loops are constructed by the
function birthdayproblem:::make_tListFunc_syntax, which
given \(n\) generates the syntax of the
necessary function nested loop function. Calling source on
this syntax string then provides a proper R function to evaluate. A
similar function
birthdayproblem:::make_tListFunc_syntax_cpp is provided to
generate an equivalent C++ function, which then using Rcpp’s
sourceCpp function can be turned into an R function. As a
side note: The nested for loops for increasing \(n\) quickly look foul, which earned it the
predicate possibly the best nested loop ever in a comment of a
stackoverflow
post concerned with the many nested loops breaking the
clang compiler on MacOS.
The above described syntax generation, evaluation and post-processing
steps necessary to compute the desired probability \(1-P(\overline{C}_n)\) are all implemented
in the function birthdayproblem::pbirthday_up (postfix:
up for unequal propabilities) in honour
of R’s pbirthday function. A method argument
allows the user to choose if the nested-loops should be computed using
"R", "Rcpp". As an alternative to the this
exact solution by Klotz
(1979) one can also compute an approximate solution described in
Mase (1992), which
is of the impressive order \(O(1)\)
while being extremely accurate (use method="mase1992"). The
R method works in acceptable time for \(n\)’s up to around 35, the Rcpp runs \(n=60\) in less than three minutes; for
larger \(n\) the approximation is to be
recommended if you don’t like waiting.
With all code in place we finally can provide Maëlle with the correct answer to her question:
n <- 26L
(p_theAnswer <- birthdayproblem::pbirthday_up(n=n, prob=newborn %$% p)$prob)## [1] 0.3399286In other words, the probability of having a name collision in a class of \(n=26\) is 34.0%. If local politics would decide to increase the maximum class size by one, the resulting probability for \(n=27\) would be: 36.1%. One more reason against increasing school class size?
Numerical Comparisons
We first test the birthdayproblem package’s
pbirthday_up function on the classical birthday problem
with equal probabilities:
c(pbirthday=pbirthday(n=26L, 365),
klotz1979_R=birthdayproblem::pbirthday_up(n=26L, rep(1/365, 365), method="R")$prob,
klotz1979_Rcpp=birthdayproblem::pbirthday_up(n=26L, rep(1/365, 365), method="Rcpp")$prob,
mase1992=birthdayproblem::pbirthday_up(n=26L, rep(1/365, 365), method="mase1992")$prob)## pbirthday klotz1979_R klotz1979_Rcpp mase1992
## 0.5982408 0.5982408 0.5982408 0.5981971works like a dream!
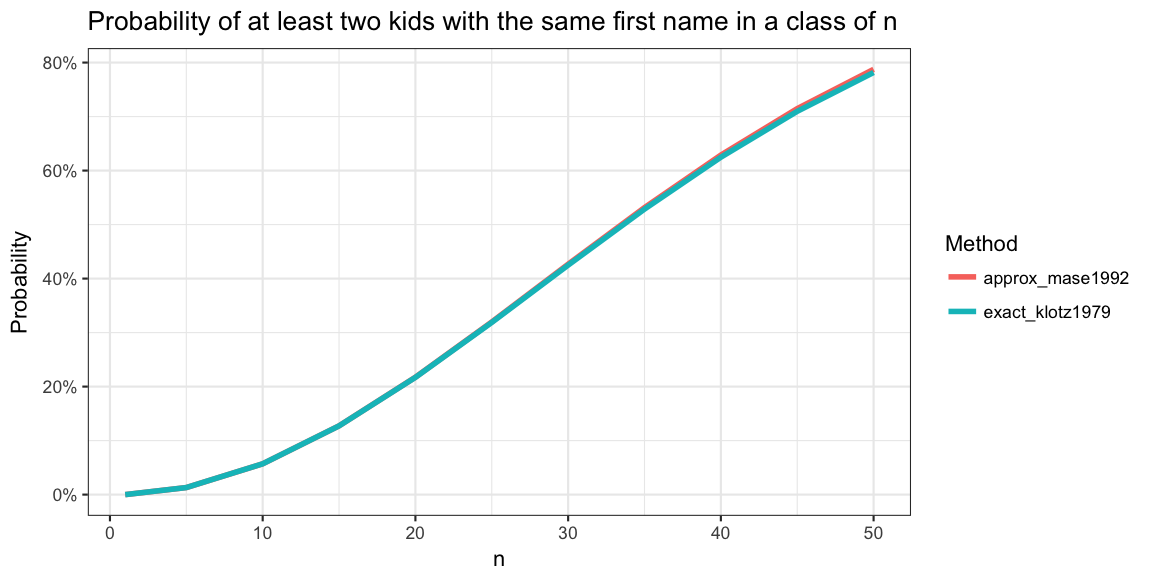
Speed-wise, the R looping approach takes 385s to compute the result for \(n=40\). The Rcpp approach on the other hand works in just 61s. The approximation by Mase (1992) only takes 0.021 s. To assess the quality of the approximation we consider a range of different \(n\):

It’s hardly possible to see the difference between the approximation and the exact solution. For better comparison, we also show the absolute error between the approximate solution and the exact solution:
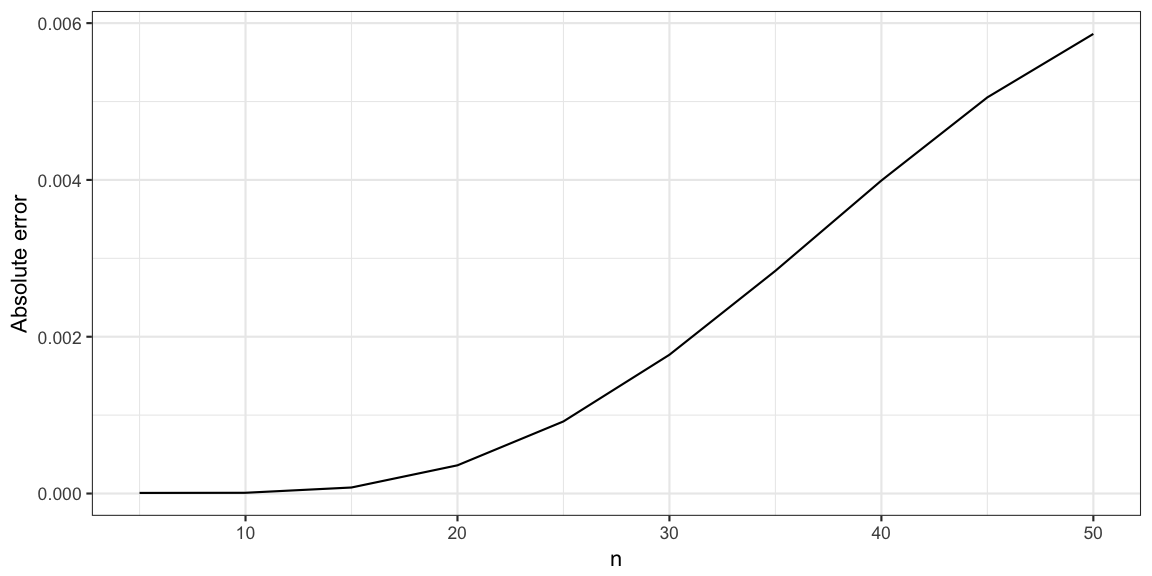
It’s amazing to see how small the error really is.
Discussion
We calculated that the probability of a name-collision in a class of \(n=26\) kids born in Berlin 2016 is 34%. Furthermore, we showed that clever mathematical approximations are better than brute-force computations, that stack-exchange rules and that Rcpp can speed up your R program considerably. Furthermore, you have been shown the best nested for loop ever! Finally, in honour of Jerome Klotz a screenshot of the Acknowledgements section of the Klotz (1979) technical report:
